Power of the server in your client
The previous generation of Version Control Systems (VCS), like Subversion, have a traditional client-server model. All the functionality relating to version control resides on the server. The client i.e. your local development machine, has access to just a single snapshot of the codebase; nothing can be done with respect to versioning without access to the VCS server.
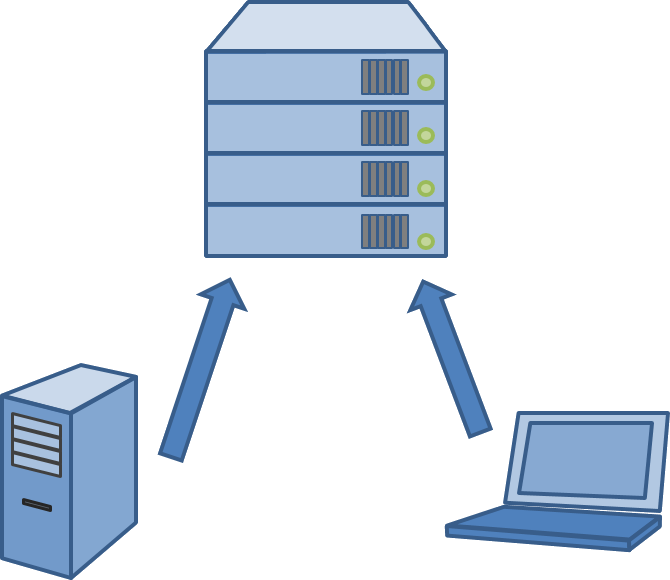
Git, however, is a Distributed Version Control System (DVCS) – there is no server-client relationship because every machine that has git installed is itself a server. What was previously your dumb client becomes a fully fledged server. Any ability your company repo server had, your portable notebook has now too.
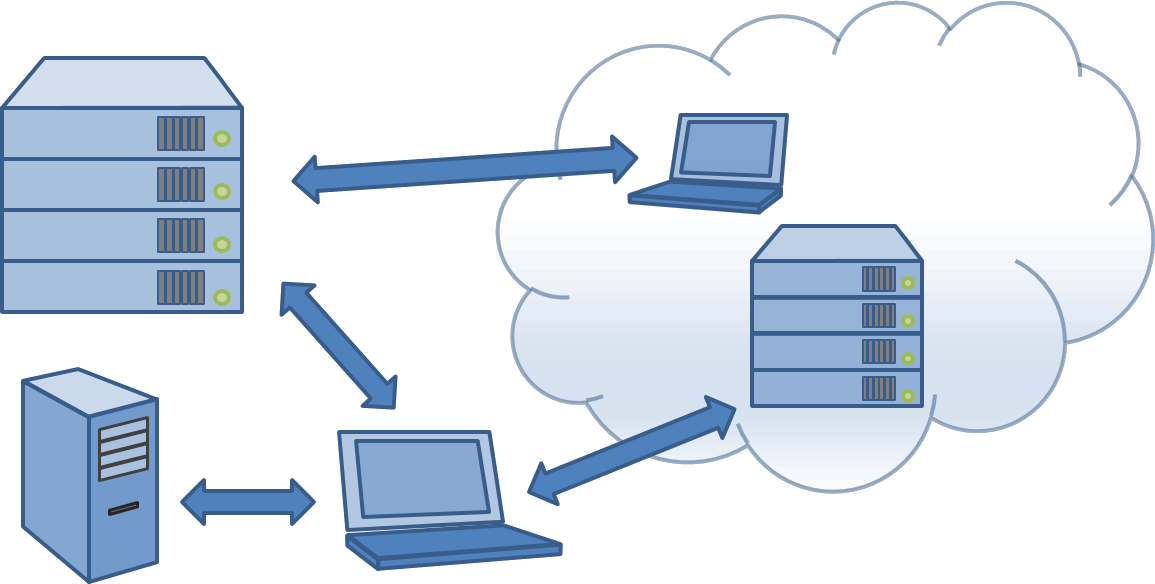
You can connect to anything and (if you open the SSH port in your firewall) anything can connect to you. Getting a codebase from a new server is a one line command. Indeed, you can work on several codebases hosted on any number of different servers hosted on your company intranet, or in open source centres like GitHub, GitLab and BitBucket.
When using git you don’t just get a copy of the latest version of the codebase as happens connecting to a VCS, you get the full history of all commits efficiently stored as a set of deltas. Say perhaps the latest cut of the code has three big, overlapping changes from different colleagues, you can see those commits in isolation without having to reconnect to the company server. Literally any git operation that’s possible on the origin repo, you can do locally on your laptop during the train ride home.
This elevated status assumed by your humble development box opens the door to several benefits impossible under the previous server-client model. The first of which described in the next post is the ability to work on multiple changes concurrently.